Understand open-source projects before you adopt them
Overctrl analyzes repositories, releases, issues, and contributors to help you spot emerging projects early, track adoption as it happens, and assess health and risk over time — without noise.
+1,000 people already joined
No spam. No GitHub access required.
GitHub shows activity.
Overctrl shows the ecosystem's














What Overctrl measures
Overctrl focuses on behavioral metrics — not vanity counts — to help you evaluate real usage, adoption, and risk.
Built for decisions, not dashboards
Stars and hype
Breakouts, adoption shifts, and abnormal behavior
Social feeds and popularity
Data-driven signals across time
One repo at a time
Cross-repo and ecosystem-level insight
Popularity lists
Early traction and breakout detection before projects go mainstream
One-size-fits-all rankings
Discovery driven by ranking algorithms across ecosystems and time
What you’ll get with Overctrl
Discovery without noise
Find emerging and breakout projects based on real traction, not hype.
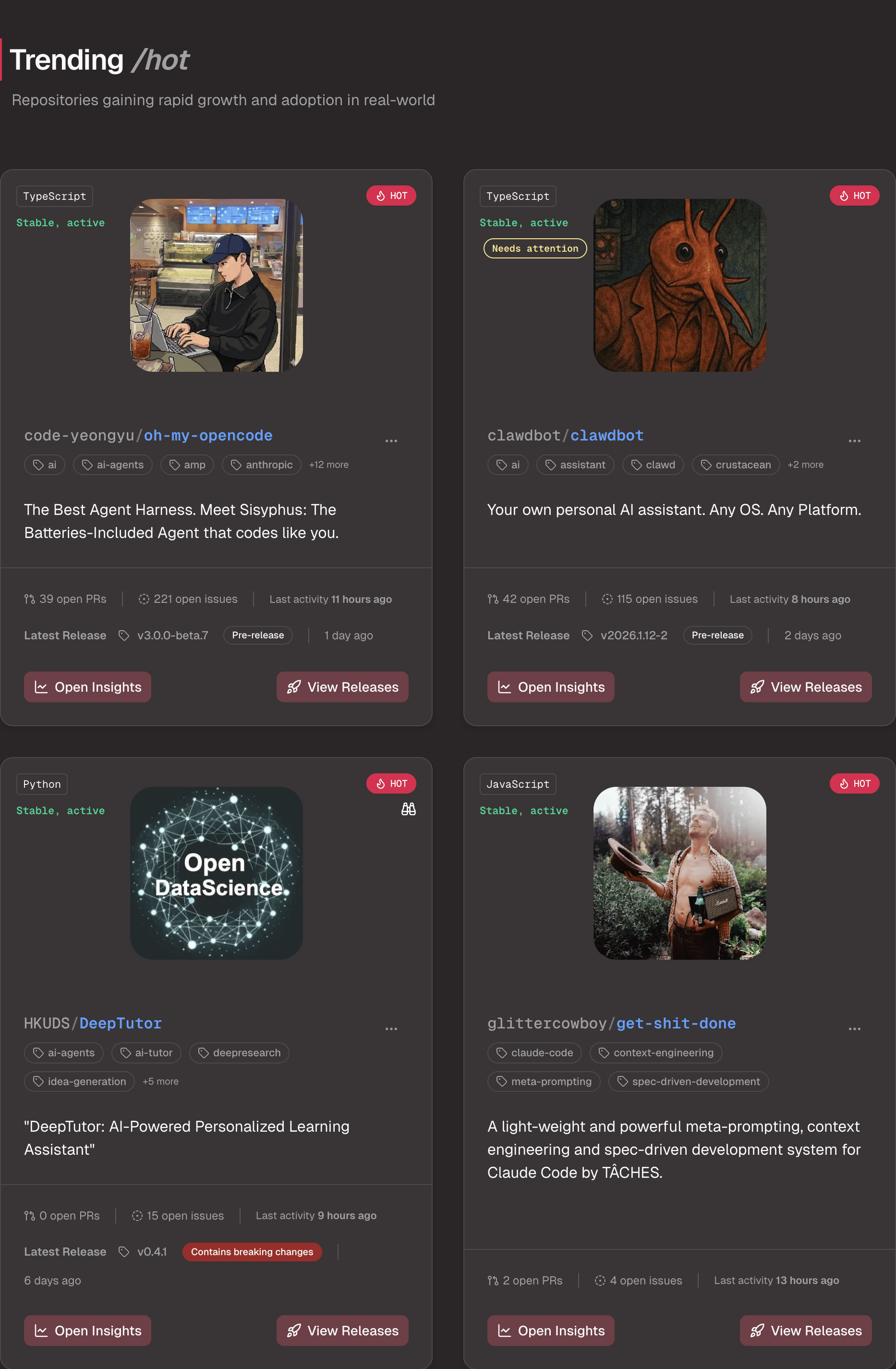
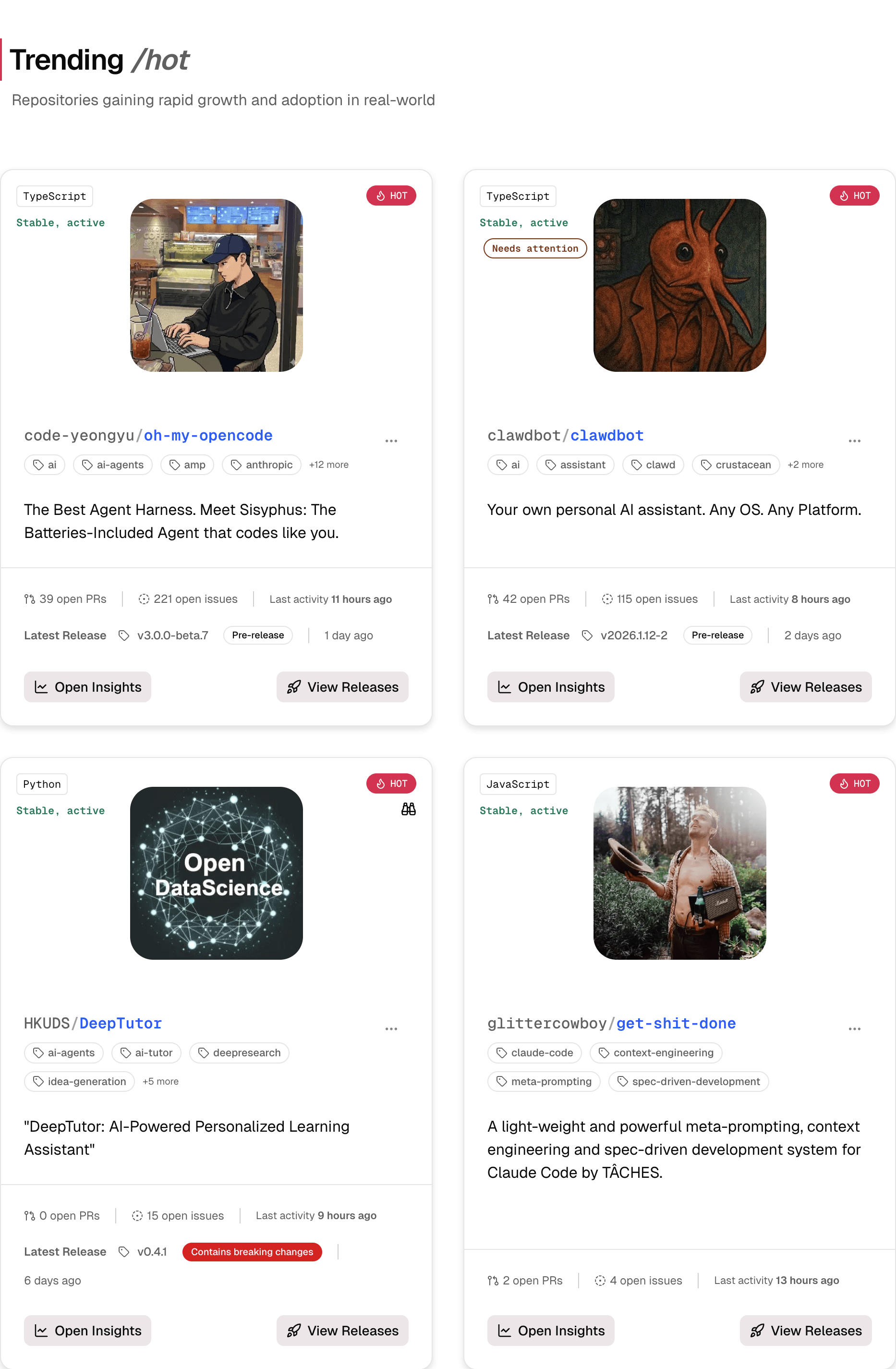


Repository intelligence
Health, activity, and maintenance signals across time.
Risk signals
Early indicators of instability, regressions, or declining maintenance.




Release impact analysis
See how releases correlate with issue spikes and adoption changes.
coming soon
Dependency awareness (coming soon)
Understand risk and adoption across dependency graphs.
Who Overctrl is for
Individual developers choosing libraries and tools
Teams evaluating dependencies and OSS risk
Maintainers monitoring adoption and issue pressure
Platform & infra engineers tracking ecosystem health
Join the Waitlist
Overctrl helps you spot emerging projects early and evaluate adoption, health, and risk over time — so you can adopt with context.
+1,000 people already joined
No spam. No GitHub access required.